This is Part 2 of a series on building AI memory that learns. Part 1 covered the landscape and why feedback is the missing primitive. This post covers how the engine works.
Architecture
Memory Layer has two layers and they change at different rates:
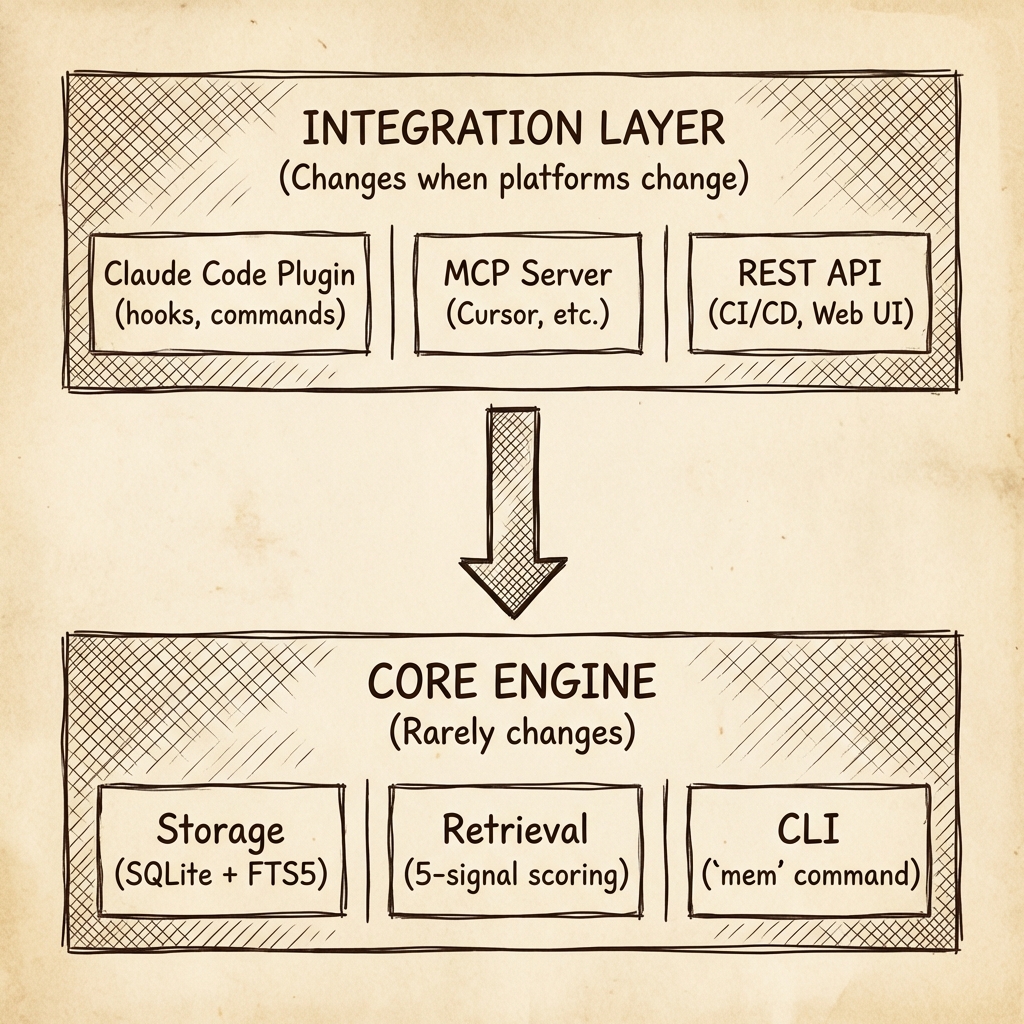
This matters because platforms evolve fast. I’ve rewritten the Claude Code integration twice already as their plugin and task system changed. The core engine hasn’t changed.
Data Model
A memory looks like this:
@dataclass
class Memory:
id: str # UUID
content: str # The actual text
category: MemoryCategory # architecture, gotcha, pattern, etc.
# Where it applies
project: str | None # None = global
# Learning signals
outcome_score: float # -1.0 to 1.0, starts at 0.0
use_count: int # Times retrieved
confidence: float # How reliable the source (0-1)
# Timestamps
created_at: datetime
updated_at: datetime
# For semantic search
embedding: bytes # 384-dim vector
The 16 categories exist because generic “memories” are hard to rank. If you ask about errors, a troubleshooting memory should rank higher than an architecture memory, even if the semantic similarity is the same.
Nine categories do most of the work:
architecture- system design decisionsconvention- coding standards (“we use snake_case”)decision- why we chose X over Ypattern- reusable code patternsgotcha- non-obvious behaviors, trapsworkaround- temporary fixestroubleshooting- how to fix specific errorscommand- useful CLI commandspreference- personal preferences
The remaining (dependency, environment, coding_style, tool_preference, context, todo, general) handle edge cases.
Storage
I prototyped with pgvector, Qdrant and Neo4j before settling on SQLite.
pgvector: Real vector indexing, scales to millions. But requires PostgreSQL running, ~500MB RAM overhead. Overkill for a personal memory store.
Qdrant: Purpose-built for vectors, billion-scale. But another service to manage. Wrong abstraction level for a local, single-user tool.
Neo4j: models relationships elegantly. I seriously considered it for dependency tracking. In practice, foreign keys covered most use cases. The operational cost wasn’t worth it.
SQLite + FTS5 + Python cosine: Zero config, single file, ships with Python. No vector indexing but at 100k memories brute-force cosine similarity still takes <100ms. The “limitations” don’t matter at personal scale.
Decision framework: what’s the simplest thing that handles 10x my current load? SQLite.
The schema:
CREATE TABLE memories (
id TEXT PRIMARY KEY,
content TEXT NOT NULL,
category TEXT NOT NULL,
project TEXT,
outcome_score REAL DEFAULT 0.0,
use_count INTEGER DEFAULT 0,
confidence REAL DEFAULT 1.0,
embedding BLOB,
created_at TEXT,
updated_at TEXT
);
-- BM25 keyword search
CREATE VIRTUAL TABLE memories_fts USING fts5(
content, category,
content='memories'
);
CREATE INDEX idx_outcome ON memories(outcome_score);
CREATE INDEX idx_project ON memories(project);
I store embeddings as BLOBs and do similarity search in Python. Not as elegant as pgvector but it works and keeps the dependency footprint small.
Why FTS5?
Vector search is great for semantic similarity-“authentication” matches “login flow” even though the words differ. But sometimes you want exact matches. If someone searches “connection reset error,” that should match memories containing those exact words, even if the embedding thinks “network timeout” is semantically closer.
BM25 (via FTS5) handles that. I run keyword search and vector search side by side and combine the scores.
Embeddings
I use sentence-transformers/all-MiniLM-L6-v2:
- 384 dimensions (small enough to store as a BLOB without pain)
- Fast inference (~10ms per embedding on CPU)
- Good quality for technical text
First run downloads the model (~100MB). Only once.
The 5-Signal Retrieval Formula
This is the core of Memory Layer:
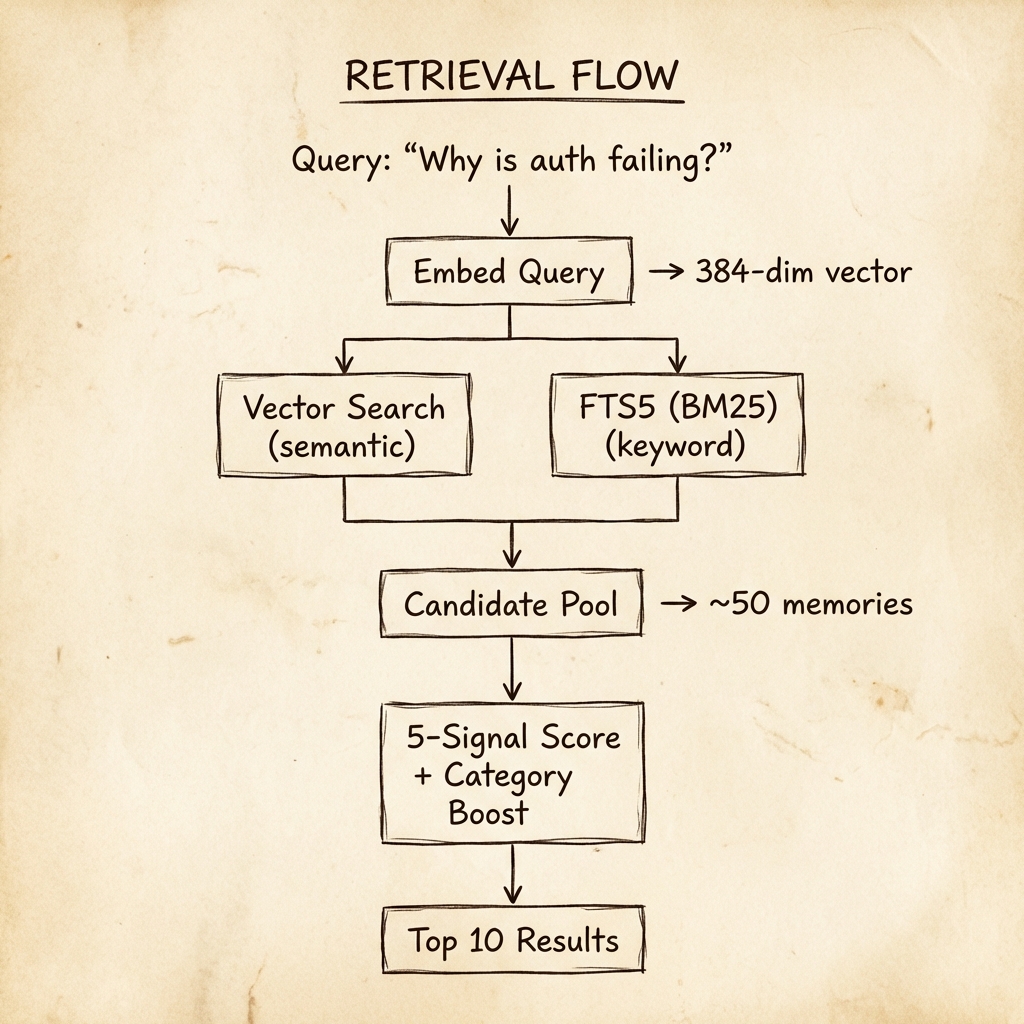
def score_memory(memory, query_embedding, detected_category=None):
# 1. Semantic similarity (35%)
semantic = cosine_similarity(query_embedding, memory.embedding)
# 2. Outcome score (25%) - the differentiator
# Normalize from [-1, 1] to [0, 1]
outcome = (memory.outcome_score + 1) / 2
# 3. Recency (15%)
days_old = (now - memory.updated_at).days
recency = exp(-days_old / 30) # 30-day half-life
# 4. Frequency (15%)
frequency = log(memory.use_count + 1) / log(100)
frequency = min(frequency, 1.0)
# 5. Confidence (10%)
confidence = memory.confidence
base = (0.35 * semantic +
0.25 * outcome +
0.15 * recency +
0.15 * frequency +
0.10 * confidence)
# Category boost
if detected_category == memory.category:
base *= CATEGORY_BOOSTS[memory.category]
return base
Why These Weights? (And What I Tried First)
The weights came from iteration, not theory.
Version 1: Pure semantic (100%) Results: 70% precision. Problem: equally-relevant memories ranked randomly. A tip that burned me yesterday ranked same as one that saved me.
Version 2: Semantic (50%) + Outcome (50%) Results: 85% precision but weird edge cases. A memory with one “worked” dominated everything. New memories never surfaced because they had no outcome data yet.
Version 3: Added recency and frequency Semantic (40%) + Outcome (30%) + Recency (15%) + Frequency (15%) Results: 88% precision. Better but new memories still struggled.
Version 4 (current): Added confidence, rebalanced Semantic (35%) + Outcome (25%) + Recency (15%) + Frequency (15%) + Confidence (10%)
5-SIGNAL WEIGHT BREAKDOWN
Semantic ████████████████████████████████████ 35% ← Core relevance
Outcome ██████████████████████████ 25% ← Learned effectiveness
Recency ████████████████ 15% ← Fresh context
Frequency ████████████████ 15% ← Usage patterns
Confidence ██████████ 10% ← Source reliability
─────────────────────────────────────
0% 25% 50% 75% 100%
The confidence signal solved the cold-start problem. New memories I explicitly add get confidence=1.0. Auto-extracted memories get 0.7-0.9. This gives new explicit memories a slight boost until they accumulate outcome data.
Why 35% semantic, not 40%? At 40%, semantic similarity dominated too much. A perfect keyword match with bad outcome history still ranked high. 35% keeps relevance primary but lets outcome data actually matter.
Why only 25% outcome? I wanted outcome to be the tiebreaker, not the dictator. At 30%+, a memory with two “worked” ratings dominated over a semantically-closer memory with no ratings. That felt wrong-relevance should still win when outcome data is sparse.
Category Boosts
When you ask about errors, troubleshooting memories should rank higher:
Query: "Why is the API returning 500 errors?"
Detected intent: troubleshooting
Before boost:
[pattern] REST API structure 0.72
[troubleshooting] Connection pool fix 0.68
After boost (troubleshooting × 1.5):
[troubleshooting] Connection pool fix 1.02 ← promoted
[pattern] REST API structure 0.72
The boosts:
- troubleshooting: 1.5x
- gotcha: 1.4x
- decision: 1.4x
- pattern, convention: 1.3x
- architecture, command: 1.2x
- workaround: 1.1x
- everything else: 1.0x
Outcome Learning
When you mark a memory as “worked” or “failed”:
def record_outcome(memory_id, result):
memory = get_memory(memory_id)
deltas = {
"worked": +0.2,
"failed": -0.3,
"partial": +0.05
}
memory.outcome_score += deltas[result]
memory.outcome_score = clamp(memory.outcome_score, -1.0, 1.0)
memory.use_count += 1
The asymmetry matters. If “worked” and “failed” had equal magnitude, a memory could oscillate forever. With −0.3 vs +0.2, consistently bad memories sink fast:
Initial: 0.0
failed: -0.3
failed: -0.6 ← effectively hidden from results
vs.
Initial: 0.0
worked: 0.2
failed: -0.1 ← one failure almost erases two successes
After a few weeks, memories with scores below −0.5 stop appearing in results. I don’t delete them-they’re archived in case the scoring was wrong-but they’re effectively gone.
Edge Cases
The “always partial” memory
Some memories are context-dependent. “Use Redis for caching” works for simple cases, fails for complex queries. Users kept marking it “partial.”
Problem: +0.05 per use meant it slowly climbed to high scores despite being unreliable. Solution: memories that haven’t been used in 30 days drift toward 0. Prevents “partial” spam from inflating scores.
The revenge downvote
User has a bad day, marks five memories “failed” in frustration.
Problem: Legitimate memories get nuked. Solution: Rate limiting on negative feedback. Max 3 “failed” ratings per hour from the same session. No limit on “worked”-positive feedback doesn’t have the same abuse potential.
The duplicate memory
User adds “use snake_case” and “always use snake_case for Python.” Both are basically the same.
Problem: Search returns both, wasting context window. Solution: Semantic deduplication at insert time. If a new memory has >0.92 cosine similarity to an existing one, prompt for merge instead of creating a duplicate.
The stale project memory
Memory says “our API uses OAuth 1.0” but the project migrated to OAuth 2.0 six months ago.
Problem: Outdated memories poison the context. Solution: Project memories inherit staleness from git activity. If the project directory hasn’t had commits in 90 days, those memories get a recency penalty.
The CLI
# Add a memory
mem add "Always use snake_case for Python functions" -c convention
# Search
mem search "naming conventions" --limit 5
# Record outcome
mem outcome mem_abc123 worked
# Get project context
mem context --project /path/to/project
# Stats
mem stats
# Start servers
mem serve --rest --port 8080 # Web UI + REST API
mem serve --mcp # MCP server for Cursor/OpenCode
The Web UI
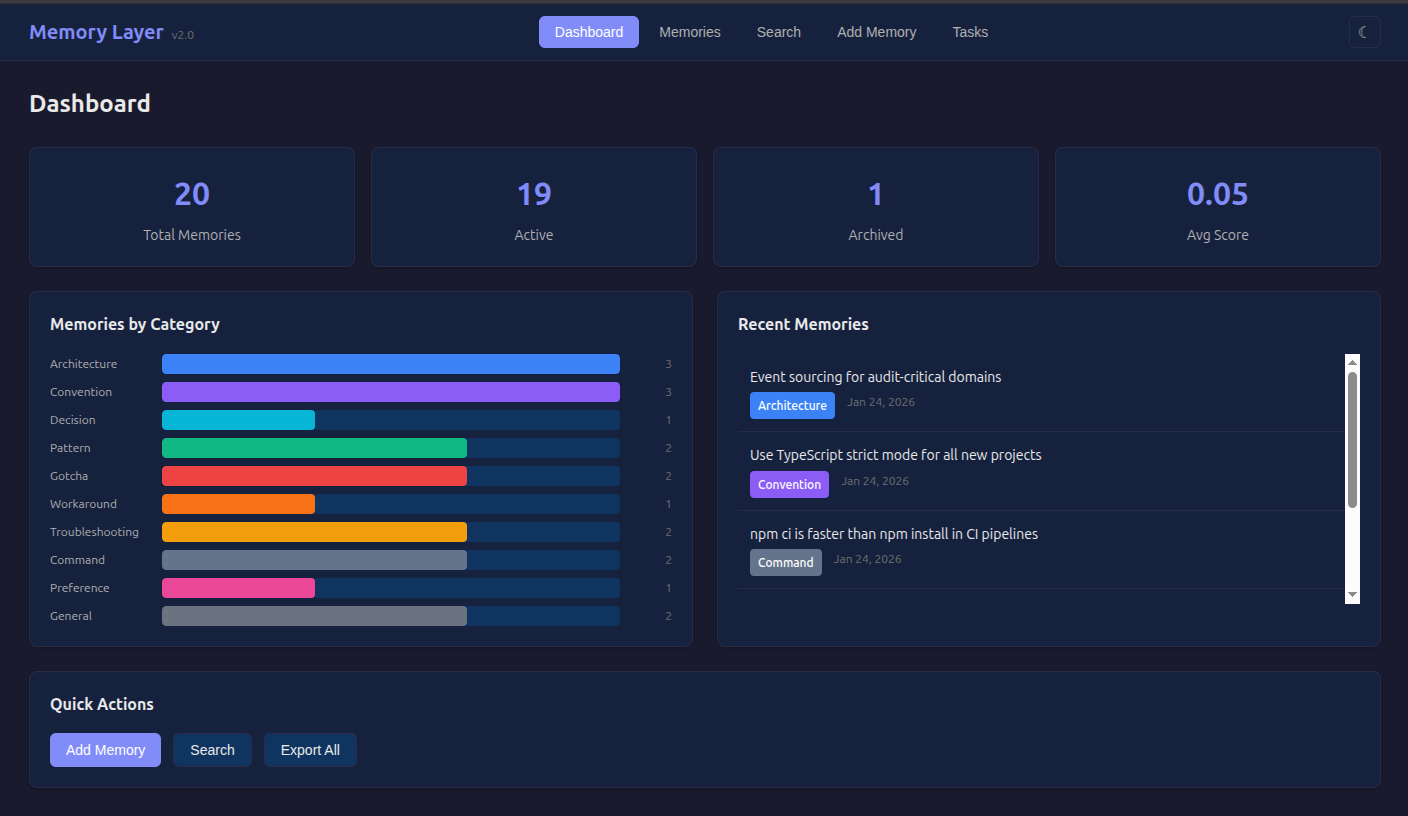
mem serve --rest --port 8080 starts a web interface at localhost:8080.
Dashboard: Total memories, active vs archived, average outcome score. Color-coded category breakdown. Recent memories.
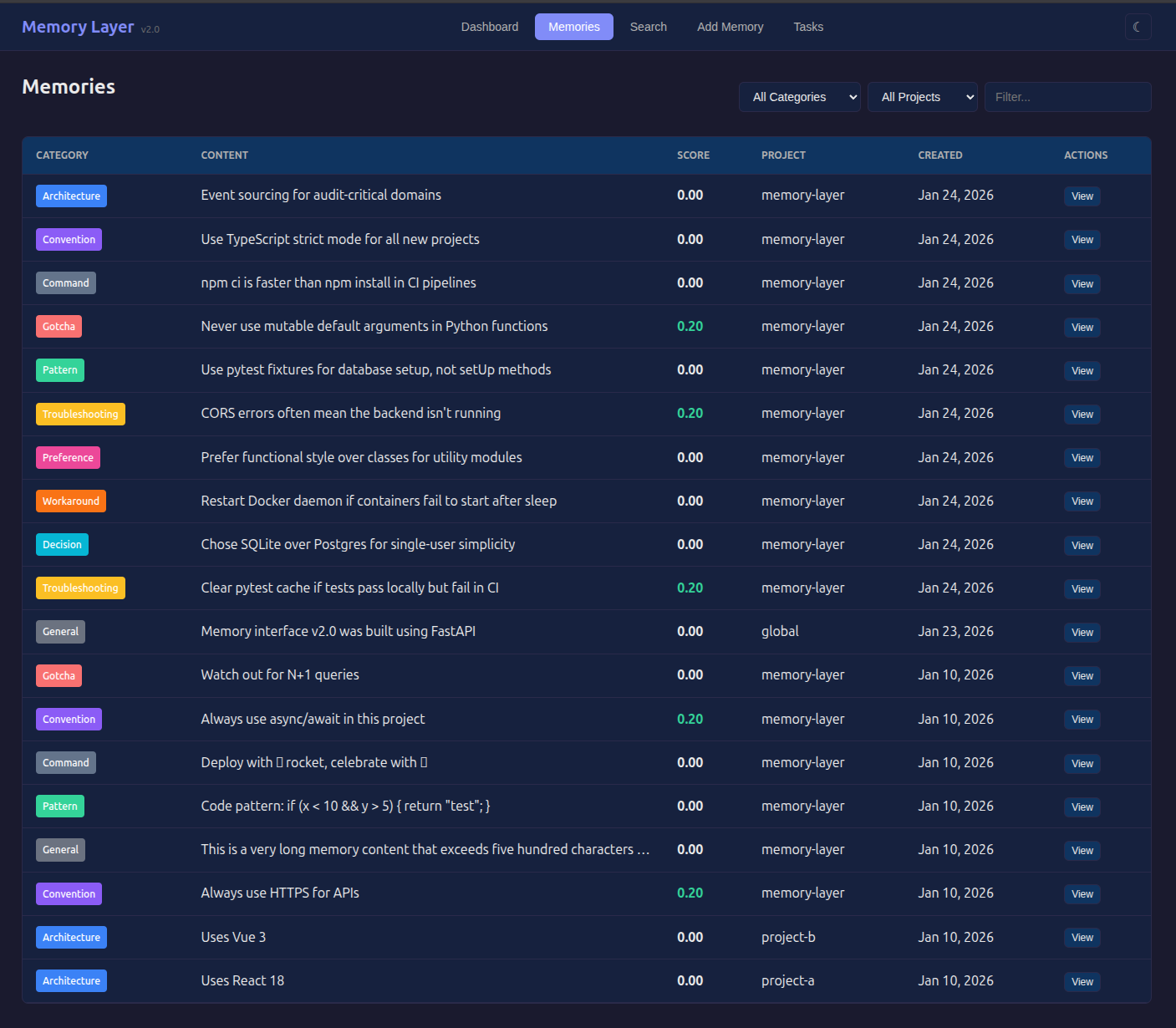
Memories view: Filterable by category, project or text. Sortable columns. Click a memory to see details and record outcomes.
Search: Two modes. Semantic search finds conceptually related memories (“auth” matches “JWT tokens”). Keyword search finds exact matches.
Tasks: Shows tasks from Beads (.beads/ directories) and Claude Code (~/.claude/todos/). Source badges distinguish them. Click to see memories linked to each task.
Theme toggle: Light/dark mode.
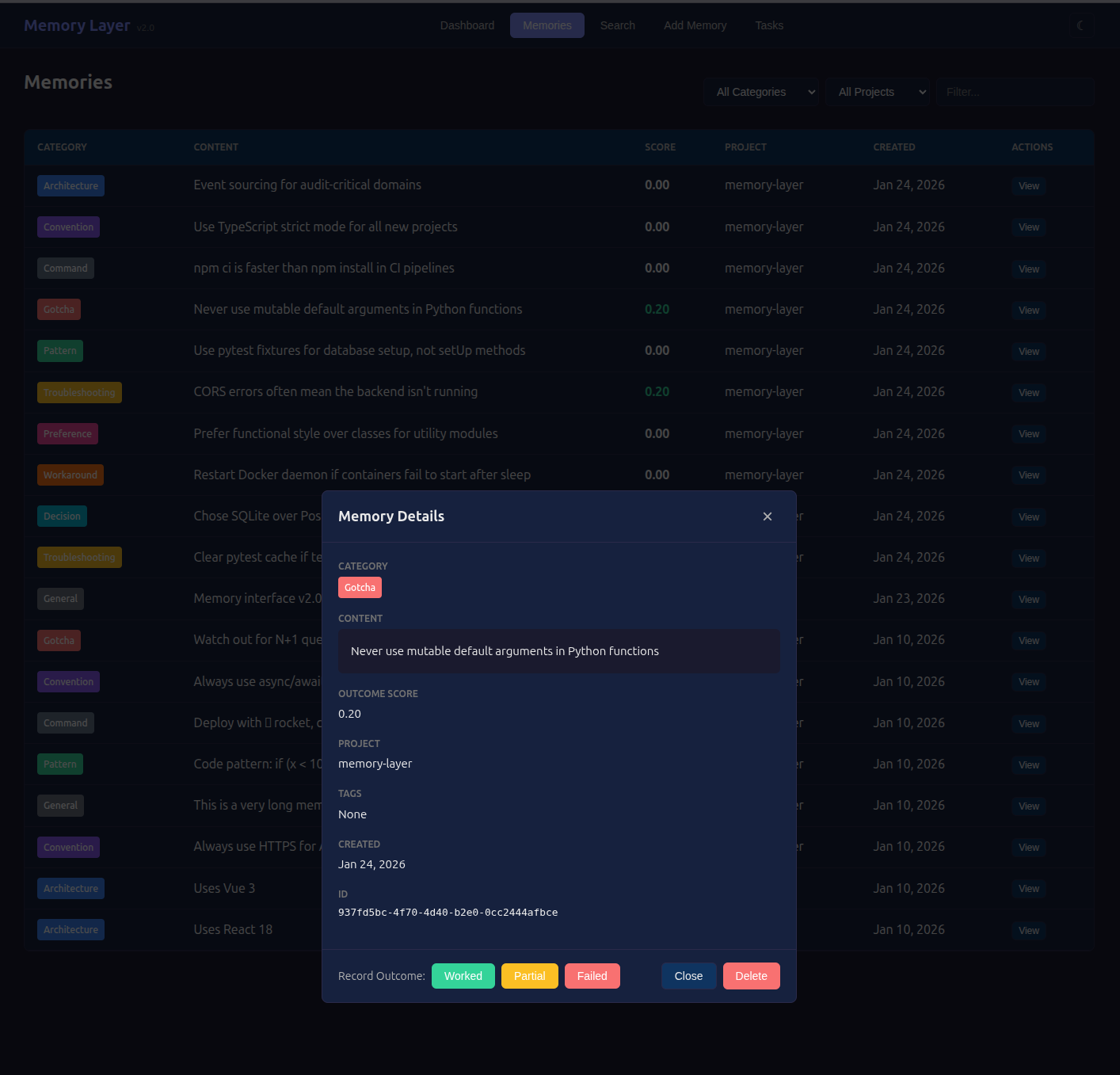
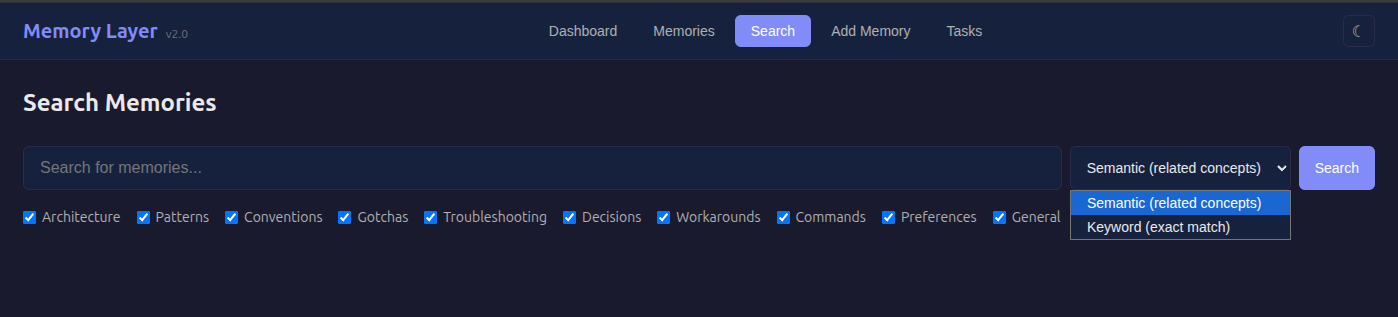
What Your Database Looks Like
After a few weeks:
$ mem stats
Total: 247 memories
Active: 231
Archived: 16 (score < -0.5)
By category:
troubleshooting 52 (21%)
convention 45 (18%)
pattern 38 (15%)
decision 34 (14%)
gotcha 28 (11%)
architecture 22 (9%)
command 15 (6%)
workaround 10 (4%)
preference 3 (1%)
Outcome scores:
High (>0.5): 43
Neutral: 188
Low (<-0.5): 16 (archived)
Database size: 12.4 MB
Results
After 6-12 weeks:
Retrieval quality: Precision went from ~70% (vector similarity only) to ~90%. The memories that kept helping surfaced first. The ones that didn’t faded away.
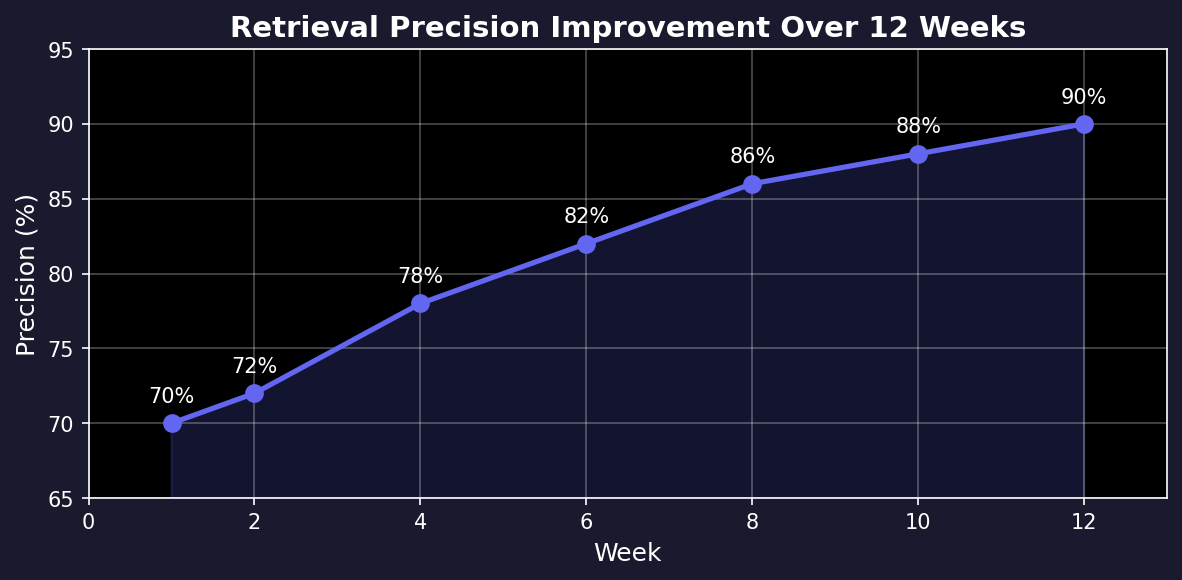
Performance: P50 retrieval is 80ms. P95 is 150ms. SQLite handles it fine.
Storage: 12MB for 250 memories. Projected ~50MB for a year of use. Not a concern.
Token savings: ~50% reduction in context re-explanation at session start. Modest but real.
Time savings: Debugging familiar issues dropped from 10-15 minutes to 2-3 minutes. This is where the real value showed up.
Lessons
SQLite is enough. I kept thinking I’d need to upgrade to something more sophisticated. I haven’t.
Hybrid search matters. Pure vectors miss obvious keyword matches. BM25 + vectors beats either alone.
Categories create real value. The ability to boost troubleshooting memories when someone asks about errors makes a noticeable difference in relevance.
Asymmetric scoring feels right. Failures should cost more. Users intuitively agree when I explain it.
The Web UI builds trust. Seeing your memories visualized-especially seeing which ones have high scores-makes the system feel less like a black box.
Series navigation:
- ← Overview: I spent 6 weeks building AI memory that learns
- ← Part 1: What I learned from 11 AI memory systems
- → Part 3: One memory store, every AI agent
Memory Layer is open source at github.com/runtimenoteslabs/memory-layer.