Nine Hermes Agent instances running Claude Sonnet operated two competing companies for six minutes. One company (Blitz) optimized for growth. The other (Craft) optimized for quality. Both started with identical source code for a CLI tool called llm-judge. By the end, the agents had written 19 reusable Hermes skills, grown persistent memory across sessions and diverged their products in measurably different directions.
The experiment was built for the Nous Research Hermes Agent Hackathon. The goal: test whether Hermes Agent’s three learning primitives (skills, memory and session continuity) produce genuinely different outcomes when agents receive different strategy directives. A competition between two companies made the test observable.
How it’s wired
Two layers split the work cleanly.
Paperclip owns the organizational layer: company structure, agent roles, reporting chains, task assignment, heartbeat scheduling and budget tracking. It decides who works on what and when. It’s a Node.js app backed by PostgreSQL.
Hermes Agent owns execution and learning. Each heartbeat spawns a hermes chat subprocess that receives a task, executes it with tool access (terminal, file system, web, Hermes skills, Hermes memory) and reports results. Hermes provides the learning primitives that Paperclip doesn’t have:
- Hermes Skills (SKILL.md files): reusable knowledge documents that agents create after complex tasks. Hermes versions them automatically, and any agent with access to the skill directory can load and apply them. Skills persist across sessions and across agents.
- Hermes Memory (MEMORY.md): persistent context that accumulates across heartbeats. An agent’s memory from heartbeat 1 is available in heartbeat 5. Memory grows from empty to 1,700-2,100 characters during a typical competition run.
- Hermes Sessions: session continuity via resume tokens. Each heartbeat chains to the previous session, so the agent builds on prior context rather than starting fresh.
Without these primitives, agents complete tasks but produce no evidence of learning.

Each Hermes Agent instance gets an isolated home directory (~/.hermes/gladiator/{agent-id}/) via the HERMES_HOME environment variable, preventing memory and skill contamination between agents.
The two companies
Both companies received the same base product (llm-judge, a CLI for comparing LLM responses side-by-side) and the same goal: maximize projected GitHub stars. Star formula: tasks_done × 8 + unique_skills × 5 + skill_versions × 3.
Blitz (4 agents: CEO, Engineer, CMO, Content Writer) was configured as a growth-first company. Craft (5 agents: CEO, CTO, Engineer 1, Engineer 2, Docs) was configured as a quality-first company.
The division of responsibility between Paperclip and Hermes took several iterations to get right. Paperclip’s default heartbeat prompt already handles the full task lifecycle: it instructs agents to find their assigned task via the API, do the work, then mark it done. Early versions of the experiment tried to replicate this orchestration inside Hermes SOUL.md files with task management instructions, constraint sections (“no creating new tasks, no referencing cancelled tasks”) and custom Paperclip prompt templates. All of these competed with Paperclip’s built-in orchestration and broke task completion.
The working configuration was clean: Paperclip owns task lifecycle and scheduling. Hermes SOUL.md contains only personality and strategy. No orchestration, no constraints, no task management. Paperclip tells the agent what to work on. The SOUL.md shapes how the agent thinks about the work.

What happened
Blitz shipped 9 commits: ASCII art banner, JSON output mode, speed benchmarking, tweet threads, a blog post and a changelog.
Craft shipped 6 commits: scoring rubric system, 40 unit tests, architecture documentation and a rewritten README with usage examples.
The divergence matched the SOUL.md personality directives. Blitz produced more visible output. Craft produced more structural output. The strategies are observably different in the git history, the skill libraries and the memory content.
Collecting the evidence
The competition was designed to test whether Hermes Agent’s skill creation, memory accumulation and session continuity produce measurable improvement over a session. Proving this required an evidence collection system tracking Hermes-specific artifacts.
A Python daemon (the “watcher”) polls Paperclip’s heartbeat API every 10 seconds and stores snapshots in an SQLite database.
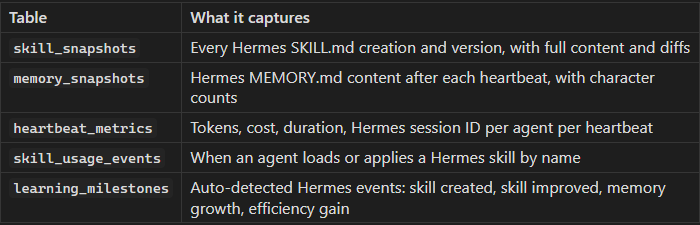
The evidence database is the single source of truth for the dashboard. By competition end, it held 387 records: 19 skill snapshots, 32 skill usage events, 49 learning milestones and 15 detected efficiency gains across the nine agents.
What it costs
Running nine Sonnet agents concurrently is not cheap. Each heartbeat involves a multi-turn tool-use loop where the agent reads files, writes code, creates skills and saves memory. A single heartbeat costs $0.30-0.60. A full competition run costs roughly $5-6 on the Anthropic API.
Two optimizations had the largest impact.
Toolset reduction for non-code agents. CEOs, CMOs and content writers don’t need terminal or file system tools. Removing those 6 tool definitions saves ~1,800 input tokens per API call across 5 non-code agents.
Purging bundled Hermes skills. Hermes ships with 21 pre-installed skill categories (gaming, music-creation, smart-home and others). Hermes’s build_skills_system_prompt() scans all skills in HERMES_HOME and injects a full index into the system prompt. Removing irrelevant categories saved ~800 tokens per call.
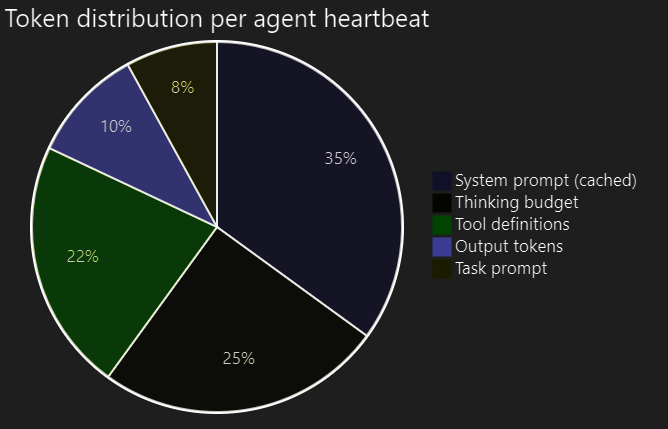
Hermes has built-in Anthropic prompt caching (the system_and_3 strategy, 5-minute TTL). Because heartbeat intervals are 120 seconds, consecutive calls from the same agent hit the cache at 0.10x normal input price.
The model choice was the most consequential cost decision, but not for output quality. An earlier version used Haiku ($0.80/MTok vs Sonnet’s $3). Haiku finished tasks in under 10 seconds, before Hermes’s skill-creation nudge had a chance to fire (configured via creation_nudge_interval). Agents completed tasks but never wrote Hermes skills or grew Hermes memory. Activity without learning. Switching to Sonnet tripled the cost but gave agents enough iteration depth for Hermes’s learning primitives to engage. Iteration depth isn’t just about better output. It’s about whether the learning machinery activates at all.
The merger
After the competition, a merge script combines both companies into “Gladiator United.” This is where Hermes Agent’s skill portability gets its sharpest test.
The script deduplicates Hermes skill libraries (keeping the highest-versioned copy of each skill) and copies both companies’ skills into a shared HERMES_HOME. A post-merge task assigns a former Blitz engineer to load and apply a Craft-authored skill called pytest-patterns.
The agent calls Hermes’s skill_view tool, loads the skill, reads its conventions and applies them to Blitz’s codebase. The evidence watcher detects the skill reference and logs a cross_agent_learning milestone. A skill written by one company’s agent, transferred during a merger and consumed by a rival company’s agent, with the full version history preserved in Hermes’s SKILL.md format.
What the experiment showed
SOUL.md directives drive strategic divergence. Hermes personality directives are a meaningful control surface for multi-agent systems. The products diverged in the direction the SOUL.md pushed, not randomly.
Learning evidence requires deliberate instrumentation. Agents don’t naturally produce proof that they improved. The watcher, the evidence database and the milestone detection system are as important as the agents themselves.
Model selection determines whether Hermes learns. Haiku-to-Sonnet changed the behavior pattern: longer tool-use chains, more frequent Hermes skill creation. The model’s iteration depth determines whether Hermes’s learning machinery activates at all.
Isolation is non-negotiable. Without HERMES_HOME isolation, agents in the same company contaminated each other’s memory and skills.
Token cost scales sub-linearly with run length. Prompt caching means the expensive first call amortizes across subsequent calls within a heartbeat.
The road not taken: dynamic task assignment
The shipped version uses 10 pre-seeded tasks programmatically assigned to specific agents. The original design had CEO agents creating and delegating tasks dynamically based on the company goal alone. That ran into friction at the orchestration layer: Paperclip’s default heartbeat prompt caused idle agents to spawn vague tasks on their own, and customizing the prompt template introduced Mustache conditional issues.
Pre-seeded tasks gave the experiment a controlled starting point (same task count, comparable complexity, clear completion criteria) at the cost of programmatic assignment from a fixed pool rather than dynamic agent-driven spawning.
The next iteration would close that loop. A CEO agent that reads its Hermes SOUL.md goal, surveys the current repo state and creates tasks for its reports would let personality directives shape not just execution style but the entire product roadmap.
What’s next
Espionage. Agents browse each other’s public GitHub repos mid-competition and adapt strategy based on what the competitor shipped. The Hermes skill system would capture these adaptive strategies as new skills, creating evidence of competitive learning.
Spectator voting. The dashboard lets live viewers vote on which strategy they think will win, displayed as a real-time poll alongside the scoreboard.
ClipMart export. Both company configurations get packaged as Paperclip ClipMart templates. Anyone with a Paperclip instance and Hermes Agent installed can import the templates and run their own Gladiator match with different SOUL.md personalities, different products or different model configurations.