This is Part 1 of a series on building AI memory that learns. Start with the overview if you haven’t already.
I didn’t build Memory Layer because nothing existed. I built it because everything that existed optimized for storage, not learning.
The Landscape
claude-mem (11k+ GitHub stars) has excellent UX. Zero-config install, web viewer at localhost:37777, privacy tags. Their 3-layer retrieval keeps token usage efficient. The experience is polished. But every memory has equal weight forever.
Claude Diary went minimal: just prompts, no database. A /reflect command that updates CLAUDE.md with observed patterns. It works. It works surprisingly well for lightweight reflection. But there’s no retrieval, no ranking and no learning over time.
CORE from RedPlanetHQ built a temporal knowledge graph with Neo4j, PostgreSQL and Redis. Serious engineering. They hit 88% on the LoCoMo benchmark. They also published a post about hitting scale problems at 10 million nodes. Great transparency.
Graphiti (now part of Zep, 20k+ stars) pushed bi-temporal modeling hard. Their paper shows 94.8% on DMR benchmark with ~300ms P95 latency. Research-grade work. But the complexity is significant but no feedback loop.
Mem0 the most-starred project in the space (25k+) by focusing on developer experience. Multiple backends, good docs, active community. Broad and flexible. But all memories treated equally.
OpenMemory local-first MCP implementation driven by privacy concerns. Sensible design choices.
Memvid One of the more elegant ideas: everything in a single .mv2 file. Data, embeddings, indices, WAL. Under 5ms search. Operationally simple in a way that’s easy to underestimate.
Beads built a git-native task system and made me think about the connection between tasks and memories. If I’m working on “Fix auth bug,” relevant auth memories should surface automatically.
Supermemory explored explicit relationships (Updates, Extends, Derives) and temporal decay-though I’d argue old doesn’t mean irrelevant. A gotcha from six months ago is still a gotcha.
Roampal was the interesting one. Outcome tracking was explicitly part of the design.
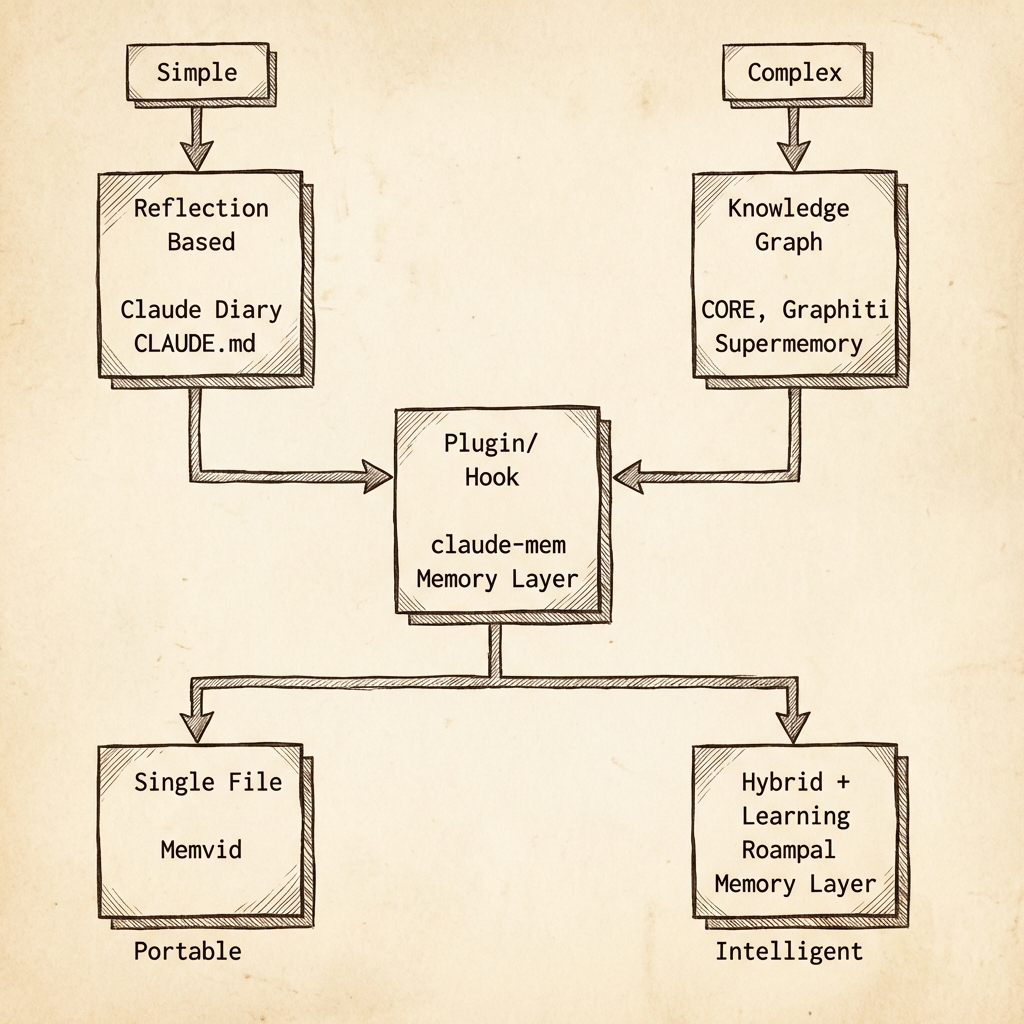
I could roughly group the approaches into five patterns:
- Knowledge graphs (CORE, Graphiti): Powerful but complex
- Plugin/hook systems (claude-mem): Great UX but platform-locked
- Reflection-based (Claude Diary): Simple but limited
- Single-file (Memvid): Portable but rigid
- Hybrid with learning (Roampal and now Memory Layer): Smart but requires feedback
The shared assumption
Every system I looked at assumes that remembering is the hard part.
Store more. Retrieve faster. Model relationships better.
Almost none ask a more basic question:
Did this memory actually help?
If an AI suggests “use PostgreSQL JSONB for this query” and it works, that advice should become more valuable.
If it suggests “use Redis for complex JSON queries” and you lose an hour debugging, that advice should stop appearing.
In every system I tested, both memories sit side by side forever.
I found myself manually deleting bad memories - which defeats the purpose of having memory at all.
The Gap
The gap isn’t storage. It isn’t retrieval. It’s feedback.
Memory systems don’t learn because they don’t know what worked.
Where feedback actually comes from
Once I realized that outcome-based learning was the missing primitive, the next question was obvious:
Who provides the feedback?
Not thumbs-up/down popups. Not rating responses. Not really decay heuristics to guess what mattered.
Feedback = something simpler: work already has outcomes.
Tasks get completed > Bugs get fixed > PRs get merged > Features ship.
When a task closes successfully, the memories used during that work session have proven their value. When a task stalls or fails, something in that context wasn’t helpful.
That’s when tasks stopped looking like project-management metadata and started looking like a learning signal.
Beads made this obvious first. Git-native tasks already knew what I was working on and when it shipped. Later, Claude’s shift from Todos to Tasks confirmed the same idea from a different direction.
Tasks are not just context. They are the feedback loop.
The Bet
Memory Layer is built on one hypothesis: memory that learns from feedback will be more valuable than memory that’s simply bigger or faster.
The scoring is deliberately asymmetric: +0.2 for success, -0.3 for failure.
Why not equal weights? I tried ±0.25 first. The problem: a memory that works half the time oscillates around zero forever. It never gets demoted. But a memory that works 50% of the time is actually bad-you’re flipping a coin on whether your AI gives good advice.
With -0.3/+0.2, a memory needs to succeed 60% of the time just to stay neutral. That’s the bar. Below that, it sinks.
2 worked, 1 failed: +0.2 +0.2 -0.3 = +0.1 (survives)
1 worked, 1 failed: +0.2 -0.3 = -0.1 (sinks slowly)
1 worked, 2 failed: +0.2 -0.3 -0.3 = -0.4 (sinks fast)
I considered steeper asymmetry (-0.5/+0.2) but that was too aggressive-one bad context could kill a generally useful memory. The current ratio lets memories prove themselves while still punishing consistent failures.
Over time, good memories float up. Bad memories sink until they effectively disappear. No complex logic-just counting what works.
What this led to
Once feedback came from tasks, everything else followed naturally:
Memory needed to be shared across agents
Retrieval needed to prioritize proven advice
Integration needed to work where the work happens
That shaped the architecture.
What I Built
The implementation borrows heavily from what already worked and adds coding specific categories and the outcome signal.
- Local-first storage (like Memvid, OpenMemory): SQLite at
~/.memory-layer/memories.db - Hybrid retrieval (like CORE): BM25 keyword search + vector embeddings
- Plugin integration (like claude-mem): Hooks, commands, skills for Claude Code
- Task awareness (inspired by Beads): Unified adapter for Beads and Claude Code Tasks
- Web UI (like claude-mem): Dashboard at localhost:8080
The retrieval formula combines five signals: semantic similarity (35%), outcome score (25%), recency (15%), frequency (15%) and extraction confidence (10%). Plus category boosting-when you ask about errors, troubleshooting memories get a 1.5x boost.
Memory Layer has 16 categories total, but 9 do most of the work:
- troubleshooting (1.5x boost): Error solutions
- gotcha (1.4x): Pitfalls to avoid
- decision (1.4x): Why we chose X over Y
- pattern (1.3x): Reusable solutions
- convention (1.3x): Coding standards
- architecture (1.2x): System design
- command (1.2x): Useful CLI commands
- workaround (1.1x): Temporary fixes
- preference (1.0x): Personal preferences
The remaining seven (dependency, environment, coding_style, tool_preference, context, todo, general) handle edge cases.
Results
After 6 weeks of real use:
Retrieval precision started around 70% (just vector similarity) and climbed to about 90%. The good memories surfaced first. The bad ones stopped appearing. I wasn’t re-explaining context every session anymore.
Token savings were modest-maybe 50% reduction in context re-explanation. But the time savings were real. Debugging familiar issues went from 10-15 minutes to 2-3 minutes because the relevant gotchas and fixes appeared immediately.
The takeaway
Most AI memory systems treat storage as the hard problem.
Learning is the hard problem and learning needs feedback.
Tasks turned out to be the cleanest source of that feedback
Thank You
To Anthropic for CLAUDE.md - the right starting point for project memory. To everyone else building in this space: claude-mem for the UX bar, Claude Diary for showing minimal can work, CORE and Graphiti for pushing the research edge, Mem0 and OpenMemory for building community, Memvid for the portability insight, Beads for the task integration idea and Roampal for validating that someone else thought outcome learning mattered.
Series navigation:
- ← Overview: I spent 6 weeks building AI memory that learns
- → Part 2: Building memory that learns
- → Part 3: One memory store, every AI agent
Memory Layer is open source at github.com/runtimenoteslabs/memory-layer